4.1. Aspectos generales de un analizador léxico
Un analizador léxico es la especificación y el diseño de programas que ejecuten las acciones activadas por patrones dentro de las cadenas.
*La principal función es leer los caracteres de entrada y elaborar como salida una secuencia de componentes léxicos que se utilizaran.
*Convierte una cadena de caracteres en una cadena de palabras.
*Una forma sencilla de crear un analizador léxico consiste en la elaboración de un diagrama que muestre la estructura de los componentes léxicos del archivo fuente, y después hacer la traducción “a mano” del diagrama a un programa para encontrar los componentes léxicos.
*Una herramienta de software que automatiza la construcción de analizadores léxicos, permite que personas con diferentes conocimientos utilicen la concordancia de patrones en sus propias áreas de aplicación.
*La gran ventaja de un generador de analizadores léxicos es que puede utilizar los algoritmos más conocidos de concordancia de patrones, con lo cual crea analizadores léxicos eficientes para los no especialistas en dichas técnicas.
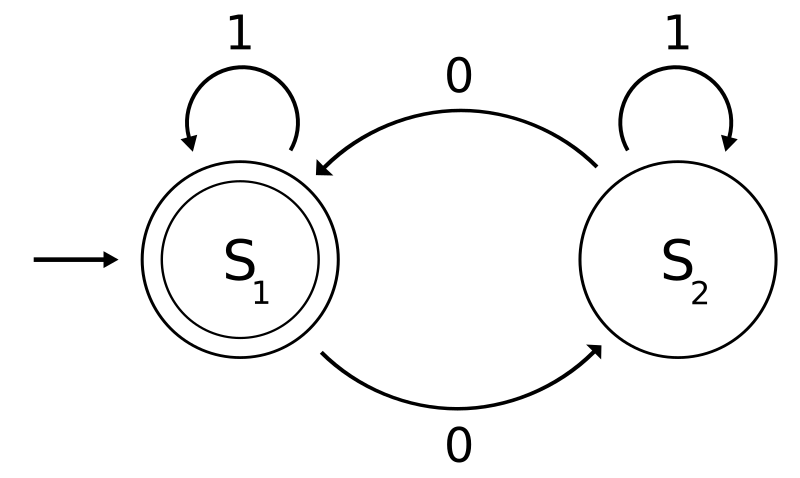
4.2. Definición de grafos y autómatas
Grafos.
Los grafos no son más que la versión general de un árbol, es decir, cualquier nodo de un grafo puede apuntar a cualquier otro nodo de éste (incluso a él mismo). Este tipo de estructuras de datos tienen una característica que lo diferencia: los grafos se usan para almacenar datos que están relacionados de alguna manera (relaciones de parentesco, puestos de trabajo, ...); por esta razón se puede decir que los grafos representan la estructura real de un problema. En lo que a ingeniería de telecomunicaciones se refiere, los grafos son una importante herramienta de trabajo, pues se utilizan tanto para diseño de circuitos como para calcular la mejor ruta de comunicación en Internet.
Autómata
Se llama autómata a cualquier mecanismo que es capaz de moverse por sí mismo. Si los autómatas se producen en serie tenemos los robots. Y, en el campo de la ficción, si el autómata tiene aspecto humano (por estar recubierto de materia orgánica por ejemplo), tenemos los androides.
También cabe llamar autómata a toda máquina que sigue un programa de instrucciones diseñado por un programador. En este sentido, los ordenadores también son autómatas. Cabe hablar también de autómatas de propósito general o universal y de autómatas de propósito limitado. En el primer caso tenemos los ordenadores convencionales, que están construidos de tal forma que pueden programarse para resolver muchos tipos diferentes de problemas, y en el segundo los computadores diseñados para realizar una tarea específica, como nuestras calculadoras o el computador de un automóvil. Por extensión, también recibe el nombre de "autómata" el programa mismo, o la arquitectura computacional en la que descansa la ejecución del programa, como es el caso de la llamada "máquina de Turing".
http://www.e-torredebabel.com/Psicologia/Vocabulario/Automatas.htm
La
teoría de autómatas es una rama de las
ciencias de la computación que estudia las máquinas abstractas y los problemas que éstas son capaces de resolver. La teoría de autómatas está estrechamente relacionada con la teoría del lenguaje formal ya que los autómatas son clasificados a menudo por la clase de lenguajes formales que son capaces de reconocer.
Un autómata es un modelo matemático para una
máquina de estado finito (FSM sus siglas en inglés). Una FSM es una máquina que, dada una entrada de símbolos, "salta" a través de una serie de estados de acuerdo a una función de transición (que puede ser expresada como una tabla). En la variedad común "Mealy" de FSMs, esta función de transición dice al autómata a qué estado cambiar dados unos determinados estado y símbolo.
La entrada es leída símbolo por símbolo, hasta que es "consumida" completamente (piense en ésta como una cinta con una palabra escrita en ella, que es leída por una cabeza lectora del autómata; la cabeza se mueve a lo largo de la cinta, leyendo un símbolo a la vez) una vez la entrada se ha agotado, el autómata se detiene.
Dependiendo del estado en el que el autómata finaliza se dice que este ha aceptado o rechazado la entrada. Si éste termina en el estado "acepta", el autómata acepta la palabra. Si lo hace en el estado "rechaza", el autómata rechazó la palabra, el conjunto de todas las palabras aceptadas por el autómata constituyen el lenguaje aceptado por el mismo.
4.3. Definición de clases, estados y tokens
Clase. Es una construcción que permite crear tipos personalizados propios mediante la agrupación de variables de otros tipos, métodos y eventos. Una clase es como un plano. Define los datos y el comportamiento de un tipo. Si la clase no se declara como estática, el código de cliente puede utilizarla mediante la creación de objetos o instancias que se asignan a una variable. La variable permanece en memoria hasta todas las referencias a ella están fuera del ámbito. Si la clase se declara como estática, solo existe una copia en memoria y el código de cliente solo puede tener acceso a ella a través de la propia clase y no de una variable de instancia.
Estados. un estado es una configuración única de información en un programa o máquina. Esto es un concepto que ocasionalmente se ha extendido en varias formas de programación de sistemas tales como lexers y Parsers.
Si el autómata en cuestión es una Máquina de estados finitos, un Autómata con pila o una auténtica Máquina de Turing, un estado es un conjunto particular de instrucciones las cuales serán ejecutadas en respuesta a la entrada de la máquina. Se puede pensar en el estado como algo análogo a la memoria principal de la computadora. El comportamiento del sistema es una función de (a) la definición del autómata, (b) la entrada y (c) el estado actual.
- Estados Compatibles son estados de una máquina de estados los cuales no tienen conflictos para ningún valor de entrada. Así para cada entrada, ambos estados deben tener la misma salida, y ambos estados deben tener el mismo sucesor (o sucesores sin especificar) o ambos no deben cambiar. Los estados compatibles son redundantes si aparecen en la misma máquina de estados.
- Estados Equivalentes son los estados de una máquina de estados los cuales, para cada posible secuencia de entrada, la misma secuencia de salida será producida - sin importar cual estado es el estado inicial.
- Estados Distinguibles son estados en una máquina de estados los cuales tienen al menos una secuencia de entrada la cual causa secuencias de salida diferentes - sin importar cual estado es el estado inicial.
Tokens. Un token es un par que consiste en un nombre de token y un valor de atributo opcional. El nombre del token es un símbolo abstracto que representa un tipo de unidad léxica; por ejemplo, una palabra clave específica o una secuencia de caracteres de entrada que denotan un identificador. Los nombres de los tokens son los símbolos de entrada que procesa el analizador sintáctico.
4.4. Matriz de transición de estados y matriz de salidas
Una tabla de transiciones es un arreglo (o matriz) bidimensional cuyos elementos proporcionan el resumen de un diagrama de transiciones correspondiente.
Tabla que muestra qué estado se moverá un autómata finito dado, basándose en el estado actual y otras entradas. Una tabla de estados es esencialmente una tabla de verdad en la cual algunas de las entradas son el estado actual, y las salidas incluyen el siguiente estado, junto con otras salidas.
Una tabla de estados es una de las muchas maneras de especificar una máquina de estados, otras formas son un diagrama de estados, y una ecuación característica.
Cuando se trata de un autómata finito no determinista, entonces la tabla de transición muestra todos los estados que se moverá el autómata.
Matriz de salidas.
4.5. Elaboración del SCANNER